Juegos de caracteres
Hoy vamos hablar sobre los diferentes juegos de caracteres que nos encontramos a la hora de crear algunas bases de datos.
Cuando hablamos de juegos de caracteres nos estamos refiriendo a la codificación de caracteres o character set y su correspondiente collation. Básicamente éstos se encargan de definir cómo se almacenan, comparan y ordenan los textos. Es decir, elegir un character set y collation correcto, es fundamental para evitar errores con los acentos, emojis, distintos idiomas o simplemente para ordenar correctamente los resultados.
Hay bases de datos que lo establecen automáticamente y otras, como MySQL o MariaDB que, a la hora de crear una base de datos, debes de especificar el tipo de codificación.
Para empezar, como hemos dicho al principio, un juego de caracteres no es otra cosa que el conjunto de caracteres que una base de datos puede almacenar. Sirve para establecer de alguna manera, cómo se codifican letras, símbolos y otros caracteres en bits.
Por otro lado, collation, se refiere al conjunto de reglas para comparar y ordenar esos caracteres (por ejemplo, si a = A, si José es diferente a JOSE, si ñ > n, etc.).
¿Por qué es importante?
Porque directamente afecta a qué idiomas podemos almacenar en nuestra base de datos (chino, árabe…) e influye también en el tamaño que ocupará el texto. Por otro lado, también afecta a la hora de realizar comparaciones, realizar una búsqueda de resultados y evitar el llamado “mojibake”.
“moji…que?”
Mojibake
El «mojibake» (término en japonés) significa literalmente «caracteres corruptos». Sucede cuando los datos de texto se interpretan con un juego de caracteres incorrecto. En otras palabras, se trata de una mala interpretación de caracteres al usar diferentes codificaciones.
Por ejemplo, si guardamos un texto en UTF-8 y luego lo leemos como si fuera ISO-8859-1, veremos algunos caracteres extraños como: é, –, ñ, etc.
¿Te suena alguna vez a ver visto eso? Seguro que si 😜
“Más profundamente”, esto sucede porque los bytes se interpretan de forma errónea, produciendo caracteres extraños o ilegibles.
Codificación de caracteres más usados
Algunos de los juegos de caracteres más usados (especialmente en MySQL, la base de datos más popular) son:
1. latin1
- Juego de caracteres tradicional basado en ISO-8859-1.
- Soporta idiomas occidentales (inglés, español, alemán…).
- Ocupa 1 byte por carácter.
- Limitado: no soporta símbolos especiales como emojis.
2. utf8
- Soporta caracteres Unicode, pero ¡OJO! en MySQL no es el UTF-8 completo.
- Solo permite caracteres de hasta 3 bytes, lo que excluye muchos símbolos modernos como emojis, caracteres musicales, algunos ideogramas chinos, etc.
3. utf8mb4
- La versión real y completa de UTF-8 en MySQL.
- Soporta todos los caracteres de Unicode, incluidos emojis.
- Usa entre 1 y 4 bytes por carácter.
Evidentemente existen otros muchos más, por ejemplo, ucs2, koi8r, etc. Esto es debido a que en el pasado no existía un estándar universal como Unicode. Cada idioma o sistema operativo tenía sus propias codificaciones (ej. Windows-1252, ISO-8859-1…).
Todos estos juegos de caracteres más antiguos, se mantienen hoy día solo por compatibilidad. Para nuevas aplicaciones, se recomienda siempre usar Unicode (utf8mb4) con el collation unicode_ci.
Como vimos antes, collation, define cómo se comparan y ordenan los caracteres.
Para entenderlo un poco mejor:
utf8mb4_general_ci: Es insensible a mayúsculas. Es lo mismo Jose que JOSE. Por cierto, el “ci” quiere decir Case Insensitive).
utf8mb4_unicode_ci: Usa las reglas Unicode completas.
utf8mb4_bin: Compara por valor binario exacto (sensible a mayúsculas y acentos). No será igual buscar José que Jose.
¿Y qué sucede en otras bases de datos?
Como hemos visto, MySQL te obliga a elegir explícitamente un juego de caracteres (como utf8mb4), sin embargo, en otras bases de datos es distinto.

PostgreSQL
En esta base de datos, por ejemplo, se usa UTF-8 como codificación por defecto en la mayoría de los sistemas operativos modernos, pero la codificación se realiza (al igual que MySQL) al crear la base de datos y usando el parámetro ENCODING.
Un ejemplo en Linux:
CREATE DATABASE mibase ENCODING 'UTF8' LC_COLLATE = 'es_ES.UTF-8' LC_CTYPE = 'es_ES.UTF-8';
LC_COLLATE: nos sirve para establecer cómo se ordenan alfabéticamente los datos. Si usamos el español, es para saber si la “ñ” va después de la “n” por ejemplo).
LC_CTYPE: se encarga de reconocer los caracteres según el idioma.
Por ejemplo, a la base de datos le ayuda a saber si un carácter es: una letra (como “a” o “ñ”), un número (como “9”), una mayúscula o minúscula, un espacio, etc.
Esto importa a la hora de convertir texto a mayúsculas o minúsculas, validar entradas de texto según reglas del idioma, etc.
Evidentemente, en PostgreSQL no solo tenemos disponible el español (es_ES.UTF-8). Si nuestro sitio es inglés, por ejemplo, podemos usar en_US.UTF-8; si es alemán el de_DE.UTF-8; para el francés el fr_FR.UTF-8 y así unos cuantos más. Pero ojo, si trabajamos en Windows, las colecciones son diferentes. Es decir, para crear una base de datos PostgreSQL en Windows, lo correcto (para español) sería:
CREATE DATABASE test_es ENCODING 'UTF8' LC_COLLATE = 'Spanish_Spain.1252' LC_CTYPE = 'Spanish_Spain.1252';
Son nombres distintos porque dependen del sistema operativo.
Y ahora la pregunta…¿Cómo saber cuáles tenemos disponibles?
Fácil:
Linux: en la terminal escribimos el comando locale -a y aparecerá una lista tipo:
- en_US.utf8
- es_ES.utf8
- fr_FR.utf8
- de_DE.utf8
- …
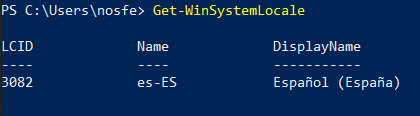
Windows: abriendo el PowerShell escribimos Get-WinSystemLocale:

SQLite
No se complica la vida, no se elige al crear la base de datos. SQLite maneja la codificación automáticamente cuando insertas texto. Todo se guarda como UTF-8.
No se complica la vida, ya que internamente usa UTF-8 o UTF-16 dependiendo de cómo tú compiles la biblioteca.

MongoDB
Tampoco necesita configurar los juegos de caracteres, ya que almacena todos los documentos BSON usando UTF-8 de forma predeterminada.
Concluyendo…
Podríamos seguir nombrado muchas más, pero resultaría en un artículo más largo y creo que lo básico y lo que se intentaba transmitir ha quedado claro con los ejemplos anteriores.
Una vez más (como siempre), espero que te haya servido, te haya gustado, hayas aprendido la diferencia y a partir de ahora y muy importante… ¡usa siempre el Unicode general! 😉
Sobre el autor
Publicaciones relacionadas:




Este artículo está publicado bajo una licencia Creative Commons Atribución-CompartirIgual 4.0 Internacional . Puedes compartirlo y adaptarlo, incluso con fines comerciales, siempre que cites al autor y mantengas esta misma licencia.